- Level Up Coding
- Posts
- Strong vs Eventual Consistency in Distributed Systems
Strong vs Eventual Consistency in Distributed Systems
(5 Minutes) | The Problem, How Each Works, and the Tradeoffs
Level Up Coding
October 23, 2025

Presented by Sonar
While AI can generate code in seconds, the human-powered process of verifying it for quality, security, and maintainability can't keep up. Sonar bridges this gap, enabling your team to "vibe, then verify”, fueling AI-enabled development while building trust into every line of code.
Strong vs Eventual Consistency in Distributed Systems
What’s worse: showing outdated data for a few seconds or halting your service entirely during a network glitch?
That’s the real-world dilemma between strong and eventual consistency in distributed systems.
Both models promise “consistency,” but they approach it in different ways. And that choice shapes your system’s speed, reliability, and complexity.
The Problem
When you scale a system, you stop having one source of truth.
A single node can guarantee that every read returns the latest write because there’s only one copy. But once you add replicas across regions for performance and fault tolerance, you introduce a simple yet critical question:
How do you keep all copies of data in sync when communication between machines isn’t perfect?
Every distributed database faces three conflicting goals:
Consistency → Every read sees the most recent write.
Availability → The system keeps serving requests, even if parts of it fail.
Partition tolerance → The system continues operating despite network delays or drops.
The CAP theorem says you can pick only two at once.
That means when a partition happens (and it will), a system must choose:
Stop serving requests until all replicas agree (favoring consistency), or
Keep serving from whatever data a replica has (favoring availability).
This decision shapes the user experience and the application’s performance.
A banking system can’t risk showing a stale balance; it must stop serving requests until replicas agree.
A social app can’t freeze every time replicas lose connection; it would rather show “good enough” data and sync later.
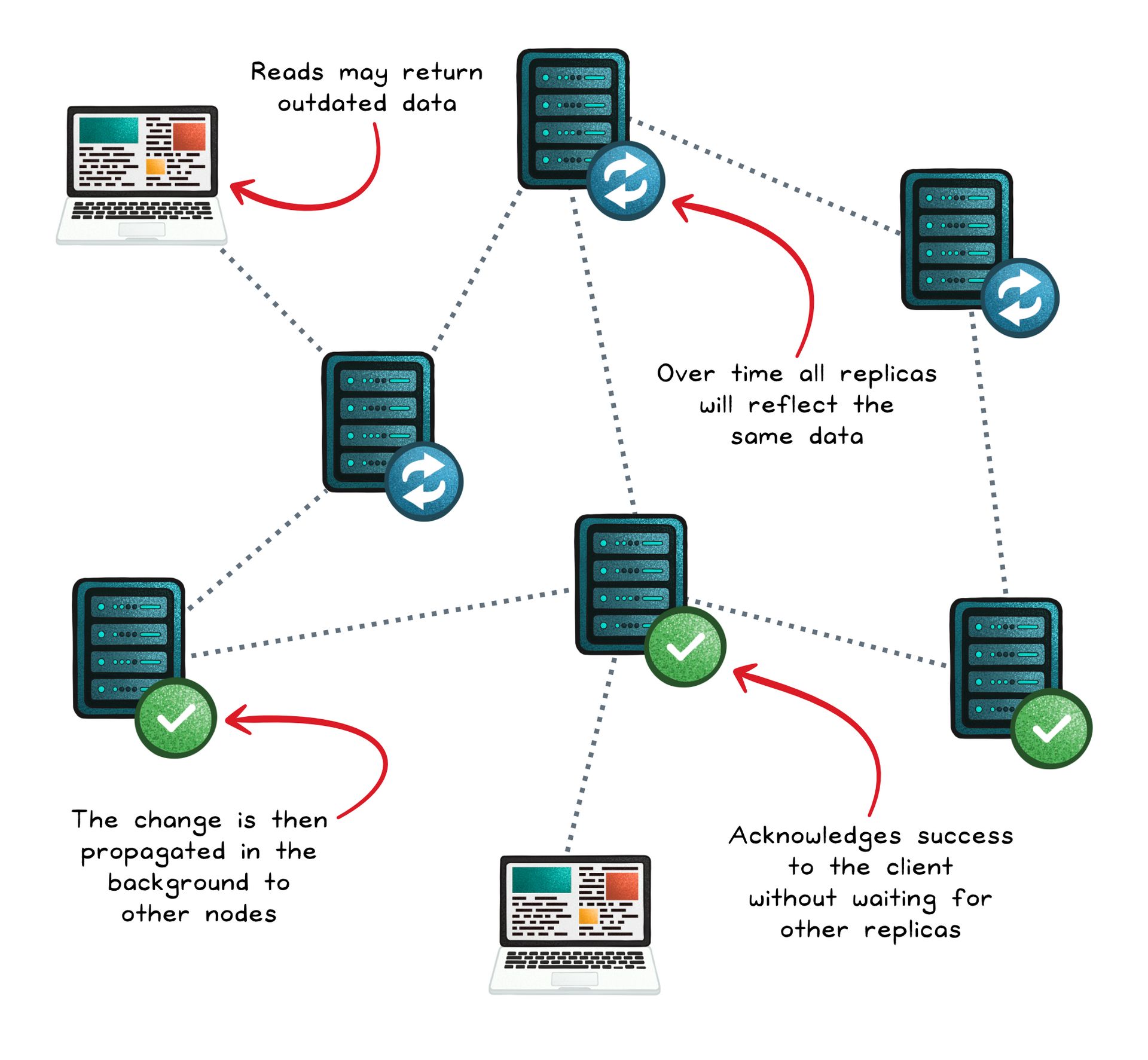
Strong Consistency
Strong consistency ensures that every read reflects the most recent successful write, no matter which replica you query. In other words, once a write is acknowledged, all clients immediately see that new value.
This model treats correctness as non-negotiable; you’d rather wait for the truth than risk reading stale data.
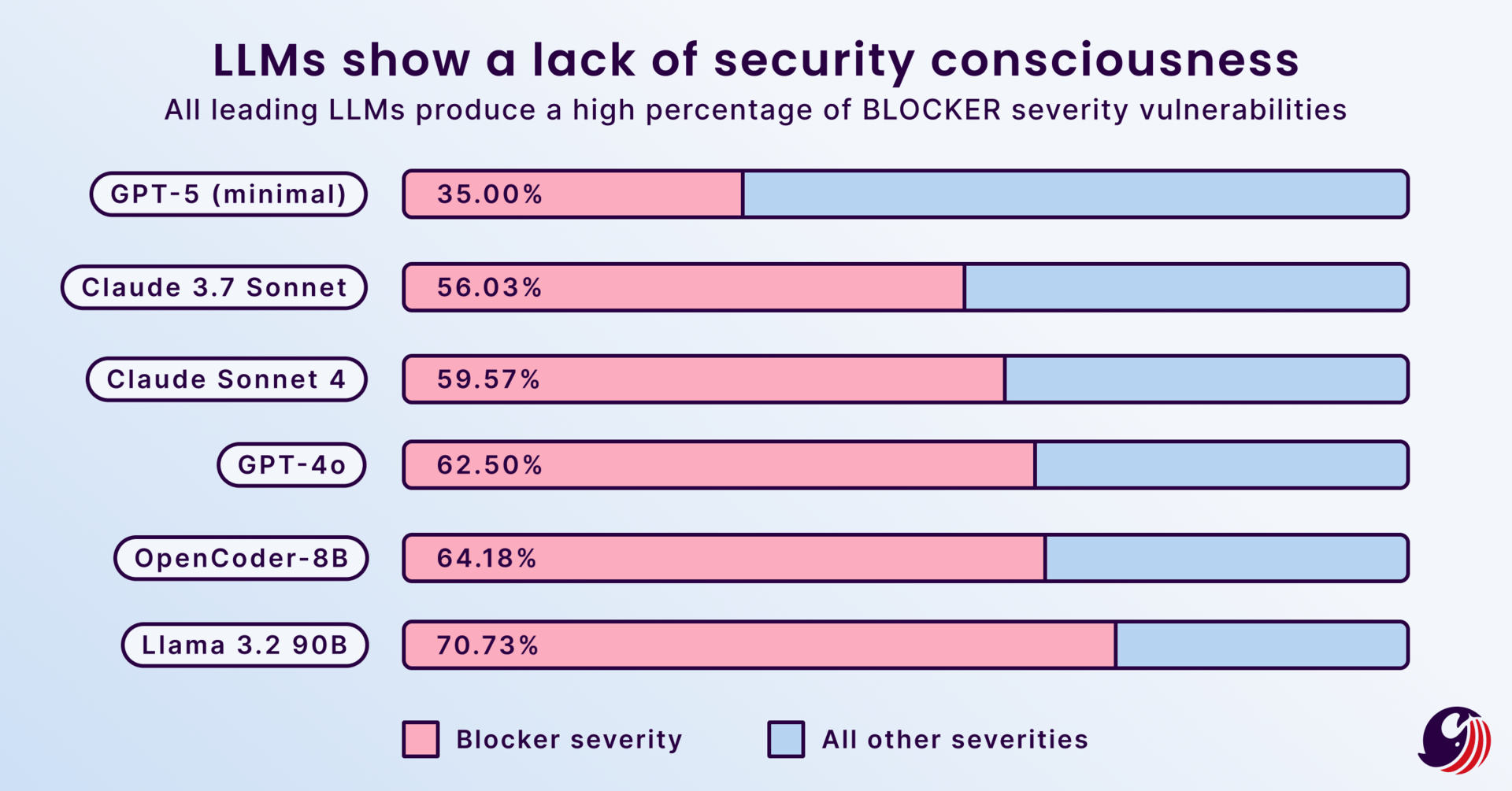
How it Works
To achieve this, distributed systems rely on tight coordination between nodes.
A client sends a write to a leader (or primary node).
The leader replicates that write to other nodes.
Each replica acknowledges the update back to the leader.
Only when enough replicas confirm (a quorum) does the leader mark the write as committed.
At that point, any node can safely serve reads with the latest data. Consensus algorithms like Paxos or Raft are often used to ensure that every node agrees on the same global order of writes, even when failures occur.
Benefits
Predictable reads → Every client sees the same up-to-date state.
Simpler application logic → No need to reconcile conflicting versions or handle stale reads.
Safer for critical domains → Prevents double-spending, race conditions, or lost updates.
Disadvantages
Higher latency → Writes (and sometimes reads) wait for confirmation from multiple replicas.
Reduced availability → During network partitions, the system may block or reject requests to maintain correctness.
Limited scalability → Global coordination adds bottlenecks as replicas and regions increase.
Eventual Consistency
Eventual consistency means that, over time, all replicas in a distributed system will reflect the same data.
It sacrifices immediate synchronization for high availability and speed. If no new updates occur, every node will converge to the same state over time, even though reads may return outdated data in the meantime.
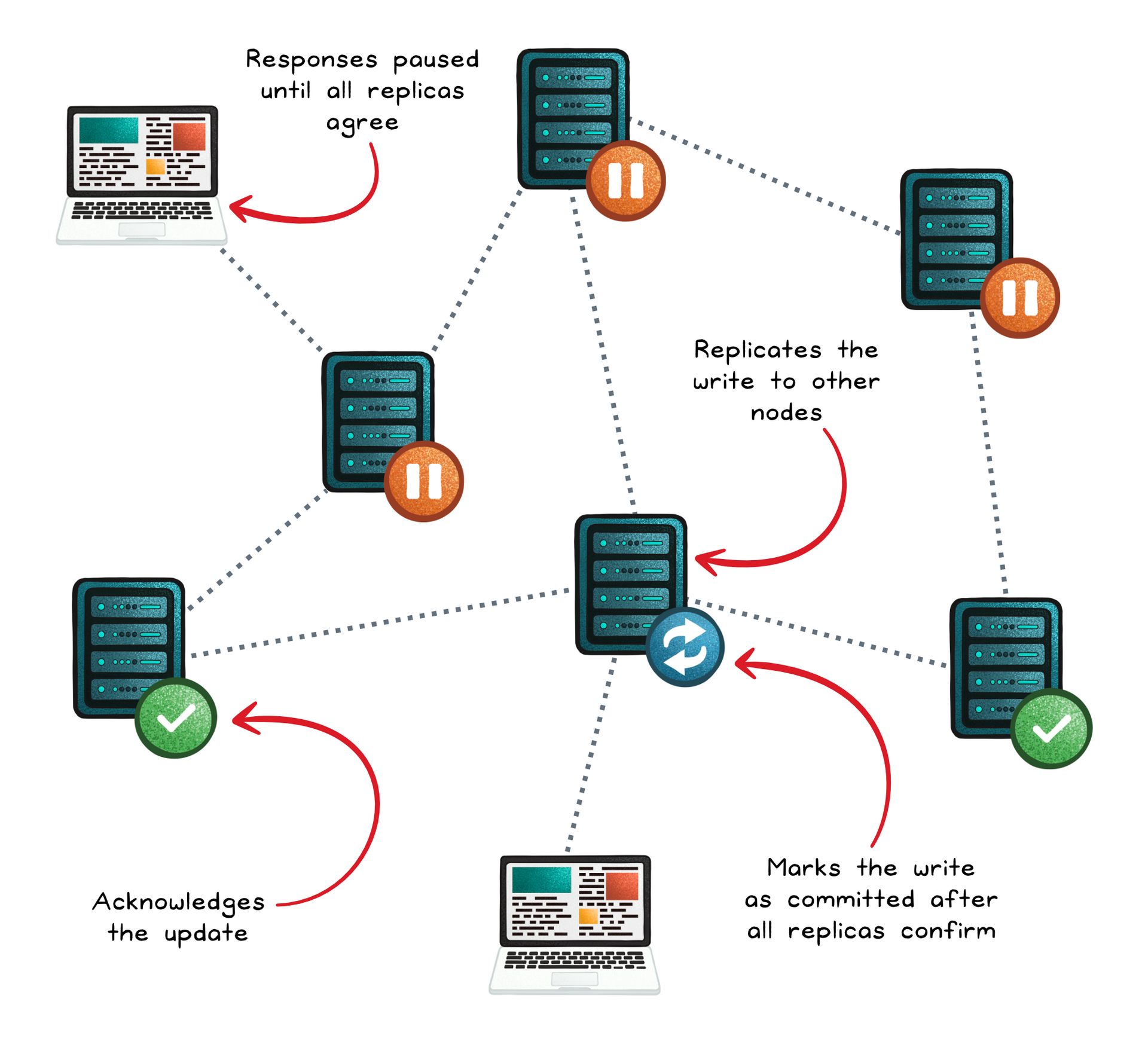
How it Works
Eventual consistency relies on asynchronous replication.
A client writes to one node (usually the nearest or most available).
That node saves the update locally and acknowledges success to the client without waiting for other replicas.
The change is then propagated in the background to other nodes through mechanisms like gossip protocols or anti-entropy syncing.
Over time, all replicas reconcile differences until they agree on the latest version.
Because updates can arrive out of order or concurrently, these systems need conflict resolution strategies (such as last-write-wins or version vectors) to merge divergent updates into a single final state. This ensures that even if replicas diverge temporarily, they’ll all settle on the same state.
Benefits
High availability → The system stays operational even when parts of the network are slow or disconnected.
Low latency → Writes and reads complete quickly since they don’t wait for global coordination.
Horizontal scalability → Nodes operate more independently, making it easy to scale across regions and handle large workloads.
Efficient resource use → Background syncing avoids constant blocking, allowing cheaper resources and better parallelism.
Disadvantages
Temporary inconsistencies → Reads may return stale data until replicas catch up.
Conflict resolution complexity → Concurrent updates must be merged correctly to avoid data loss or corruption.
Developer overhead → Applications need to handle stale reads, retries, and reconciliation logic.
Unsuitable for critical operations → Systems like banking or inventory management can’t risk showing outdated or conflicting data.
Summary
At the core, this debate isn’t about which approach is right or wrong; it’s about what you value more: always reading the most up-to-date data or keeping your system responsive and available no matter what.
Choosing the Right Model
Use strong consistency when accuracy is non-negotiable → like financial transactions, stock levels, or systems that coordinate resources. It guarantees the one true state, even if that means waiting or rejecting requests.
Use eventual consistency when responsiveness and uptime matter most → like user feeds, caching, or globally distributed services. It keeps your system fast and fault-tolerant, even if it means showing slightly outdated data.
Both models solve the same problem (synchronizing data across unreliable networks) but they make opposite trade-offs between correctness, latency, and fault tolerance. Understanding where your system sits on that spectrum helps you decide when truth matters more than speed.
That wraps up this week’s issue of Level Up Coding’s newsletter!
Join us again next week where we’ll explore and visually distil more important system design concepts.